どうも、みむらです。
最近は在宅時は NACK5 さんを聞きながら仕事をしていることが増えているのですが、
さてさて。
Hyper-V 上の Linux 上で GPU を使うというのがあります。
色々な記事はあったのですが Linux カーネルを新しめ (執筆時点では 6.8) のもので組むのには、少し手間が掛かってしまったのでここにまとめてみようかと。
なおこの記事は「GPU パーティション分割」機能を用いた構築例となります。
詳細についてはこのあたりを参照ください:https://learn.microsoft.com/ja-jp/windows-server/virtualization/hyper-v/gpu-partitioning
今回は、諸事情で Kali Linux (Debian) での紹介となりますが、素のDebian や Ubuntu はもちろん、他のディストリビューションでも転用出来ると思います。
1. ゲスト側の Linux で必要なファイルを WSL2 環境から取り出す
WSL のシステムディストリビューションを起動し、中から必要なファイルを取り出します。
WSL2 はユーザがインストールしたディストリビューション(ユーザディストリビューション)をコンテナとして動かす仕組みになっています。
余談ですが、とくに手を入れていなければ CBL-Mariner が走っています。https://github.com/microsoft/azurelinux
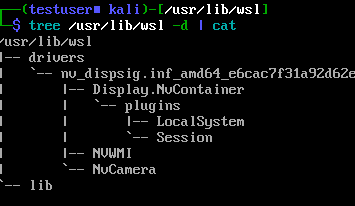
今回ここから取り出すのは、/usr/lib/wsl/lib 以下にあるファイル群になります。
Windows 環境側に作業用フォルダを作り 、必要なファイルをコピーして tar を作ります。
なお下記のコマンド例では、作業用フォルダのパスは「 C:\Users\mimura1133\Desktop\work_wsl 」にあるものとします。
・方法1:ディスク容量を気にしない場合
この場合はシンプルに
ただし、不要なドライバが大量に含まれるため、かなり大きくなります。
cd /usr/lib/wsl
bsdtar cf - lib | gzip > /mnt/(Windows 側作業フォルダまでのパス)/lib.tar.gz
bsdtar cf - drivers | gzip > /mnt/(Windows 側作業フォルダまでのパス)/drivers.tar.gz
# コマンド実行例:
# cd /usr/lib/wsl
# bsdtar cf - lib | gzip > /mnt/c/Users/mimura1133/Desktop/work_wsl/lib.tar.gz
# bsdtar cf - drivers | gzip > /mnt/c/Users/mimura1133/Desktop/work_wsl/drivers.tar.gz以上の手順で作成された lib.tar.gz と drivers.tar.gz が後ほど必要になります。
・方法2:必要最小限のデータのみを取り出す場合
下記の手順では必要最小限のデータのみを取り出します。
1. /usr/lib/wsl/lib ディレクトリ以下を取り出す
cd /usr/lib/wsl
bsdtar cf - lib | gzip > /mnt/(Windows 側作業フォルダまでのパス)/lib.tar.gz
# コマンド実行例:
# cd /usr/lib/wsl
# bsdtar cf - lib | gzip > /mnt/c/Users/mimura1133/Desktop/work_wsl/lib.tar.gz2. 現在使用しているグラフィックドライバをコピーする
Windows 側の PowerShell で下記のコマンドを実行して、ドライバを特定します。
Get-CimInstance -ClassName Win32_VideoController -Property * | Format-Table InstalledDisplayDrivers -AutoSize -Wrap実行例:
上記の例の場合は、 C:\Windows\System32\DriverStore\FileRepository\nv_dispsig.inf_amd64_e6cac7f31a92d62e 以下に必要なファイル群があることが分かります。
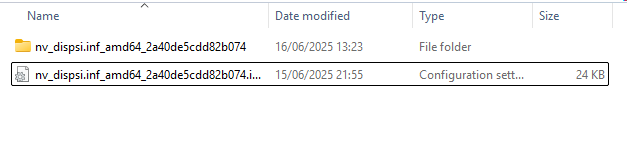
上記の結果を用いて、必要なドライバをフォルダごと作業フォルダの “drivers” 以下にコピーします。
# カレントディレクトリ移動
cd C:\Windows\System32\DriverStore\FileRepository
# ドライバをフォルダごとコピー
robocopy /mir (必要なドライバのフォルダ名) (作業フォルダまでのパス)\drivers\(必要なドライバのフォルダ名)
# ini ファイルをコピー
copy (必要なドライバのフォルダ名).ini (作業フォルダまでのパス)\drivers
# コマンド実行例:
# cd C:\Windows\System32\DriverStore\FileRepository
# robocopy /mir nv_dispsi.inf_amd64_2a40de5cdd82b074 C:\Users\mimura1133\Desktop\work_wsl\drivers\nv_dispsi.inf_amd64_2a40de5cdd82b074
# copy nv_dispig.inf_amd64_0afec3f2050014a0.ini C:\Users\mimura1133\Desktop\work_wsl\driversコピーが完了した後、drivers フォルダの中は下記のような状態になります。
3.ドライバを tar で固める
WSL2 が動く Windows であれば、最初から tar が使えるようになっています。
cd (作業フォルダまでのパス)
tar zcvf drivers.tar.gz drivers実行例:
以上で drivers.tar.gz と lib.tar.gz が出来ました。以降でこれらのファイルが必要になります。
2. Kali Linux をインストールする
通常通りのインストールを実施します。
公式サイトからの VM イメージのダウンロード、iso を用いたインストール、Hyper-V のクイック作成等方法は問いません。
なお、iso からインストールを行う場合は「第2世代」
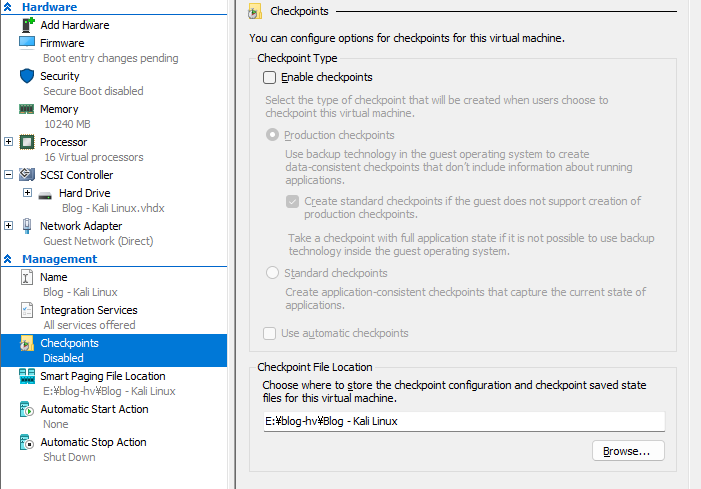
3. 仮想マシン (VM) の設定を変更する
VMの設定を行います。
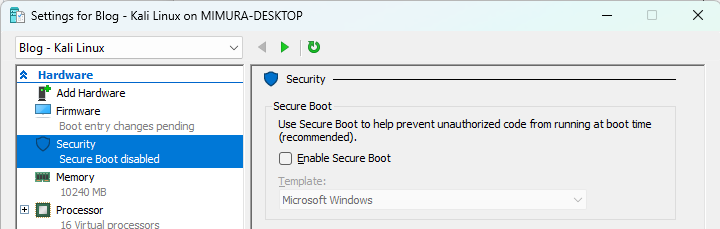
既にVM が起動している場合はシャットダウンをおこなった上で
・セキュアブートが無効 になっているか
・動的メモリは無効 になっているか
・チェックポイント(スナップショット)は無効 になっているか
続けて Powershell を管理者権限で起動
# VM の情報を取得
$vm = Get-VM -Name "<VM名, ワイルドカードも使えます>"
# GPU の追加
$vm | Add-VMGpuPartitionAdapter
# Memory Mapped I/O 領域の設定
$vm | Set-VM -GuestControlledCacheTypes $true -LowMemoryMappedIoSpace 1GB -HighMemoryMappedIoSpace 32GB4. VM 内に必要なデータをコピーする
VM を起動し、1つめのステップで作成した lib.tar.gz と drivers.tar.gz を Linux VM 内にコピーします。
※ 2024.06.17 現在、Kali Linux ではこの段階では GUI (Xorg) の起動に失敗します。
ファイルのコピーには SCP や curl 等を用いることもできますが、
管理者権限で起動した PowerShell を用いて
# VM の情報を取得。
# (Step 3 で行っている場合は下記コマンドは不要)
$vm = Get-VM -Name "<VM名, ワイルドカードも使えます>"
# ファイルコピー
$vm | Copy-VMFile -FileSource Host -SourcePath .\lib.tar.gz -DestinationPath /
$vm | Copy-VMFile -FileSource Host -SourcePath .\drivers.tar.gz -DestinationPath /上記手順が完了次第、Linux VM にログインし、ルート直下に lib.tar.gz と drivers.tar.gz があること を確認します。
(Ctrl + Alt + F1 を押下してログイン画面を表示し、ログインします。)
実行例:
5. コピーした tar.gz ファイルを展開する
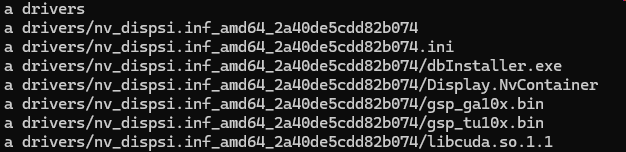
コピーしたファイルを VM 内の /usr/lib/wsl 以下に展開します。
# ディレクトリを作成
sudo mkdir /usr/lib/wsl
# lib を展開
sudo tar zxvf lib.tar.gz -C /usr/lib/wsl
# drivers を展開
sudo tar zxvf drivers.tar.gz -C /usr/lib/wsl
# 権限を設定
sudo chmod -R 0555 /usr/lib/wslコピー後、下記のようなディレクトリ構造になっていることを確認出来れば OK です。
6. コピーしたファイルにパスを通す
下記コマンドを実行しパスを通します。
echo "/usr/lib/wsl/lib" | sudo tee /etc/ld.so.conf.d/ld.wsl.conf
sudo ldconfig
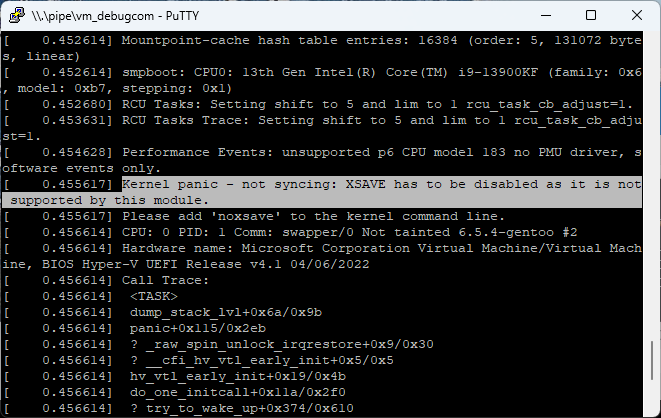
# libcuda.so.1 に関するエラーが出ますが、無視してOKです。7. カーネルドライバをインストールする
WSL2 に組み込まれているカーネルモードドライバを組み込みます。
この部分のコードは WSL2 のカーネルのソースコードにしかなく、通常、最新のカーネルコードを用いる場合Microsoft 社が公開しているコードでは手入れが必要です。
とても親切なかたがインターネット上にはいらっしゃって、https://github.com/Nevuly/WSL2-Linux-Kernel-Rolling
今回はここのコードを用いて、今走っているカーネル向けのドライバを作って入れ込む戦略を採ります。入れ込む部分のコードについても、下記に公開されているものをお借りして進めます。
https://gist.github.com/krzys-h/e2def49966aa42bbd3316dfb794f4d6a
・必要なプログラム・ファイルのインストール
sudo apt install linux-headers-amd64 dkms git・カーネルモードドライバの作成・インストール
先ほどのサイトからお借りして少し編集したものを下記に示します。
#!/bin/bash -e
#
# The original version is https://gist.github.com/krzys-h/e2def49966aa42bbd3316dfb794f4d6a
#
if [ "$EUID" -ne 0 ]; then
echo "Swithing to root..."
exec sudo $0 "$@"
fi
git clone --depth=1 https://github.com/Nevuly/WSL2-Linux-Kernel-Rolling
cd WSL2-Linux-Kernel-Rolling
VERSION=$(git rev-parse --short HEAD)
cp -r drivers/hv/dxgkrnl /usr/src/dxgkrnl-$VERSION
mkdir -p /usr/src/dxgkrnl-$VERSION/inc/{uapi/misc,linux}
cp include/uapi/misc/d3dkmthk.h /usr/src/dxgkrnl-$VERSION/inc/uapi/misc/d3dkmthk.h
cp include/linux/hyperv.h /usr/src/dxgkrnl-$VERSION/inc/linux/hyperv_dxgkrnl.h
sed -i 's/\$(CONFIG_DXGKRNL)/m/' /usr/src/dxgkrnl-$VERSION/Makefile
sed -i 's#linux/hyperv.h#linux/hyperv_dxgkrnl.h#' /usr/src/dxgkrnl-$VERSION/dxgmodule.c
echo "EXTRA_CFLAGS=-I\$(PWD)/inc" >> /usr/src/dxgkrnl-$VERSION/Makefile
cat > /usr/src/dxgkrnl-$VERSION/dkms.conf <<EOF
PACKAGE_NAME="dxgkrnl"
PACKAGE_VERSION="$VERSION"
BUILT_MODULE_NAME="dxgkrnl"
DEST_MODULE_LOCATION="/kernel/drivers/hv/dxgkrnl/"
AUTOINSTALL="yes"
EOF
dkms add dxgkrnl/$VERSION
dkms build dxgkrnl/$VERSION
dkms install dxgkrnl/$VERSION上記の内容をダウンロードしやすいよう下記の gist にもアップロードしました。
https://gist.github.com/mimura1133/895b2f5f79ca1de1fbd7b0acf10358d6
8. CUDA の環境をインストールする
nvidia-cuda-toolkit のインストールと、ライブラリのリンクの張り替えを行います。
# cuda toolkit のインストール
sudo apt install nvidia-cuda-toolkit
# 不要な追加パッケージの削除
sudo apt remove nvidia-kernel-dkms nvidia-modprobe nvidia-kernel-common
# libcuda.so が cuda toolkit のモノになっているので張り替える。
sudo rm /usr/lib/x86_64-linux-gnu/libcuda.so
sudo rm /usr/lib/x86_64-linux-gnu/libcuda.so.1
sudo ln -s /usr/lib/wsl/lib/libcuda.so /usr/lib/x86_64-linux-gnu/libcuda.so
sudo ln -s /usr/lib/wsl/lib/libcuda.so.1 /usr/lib/x86_64-linux-gnu/libcuda.so.1ここまで来たら一度再起動
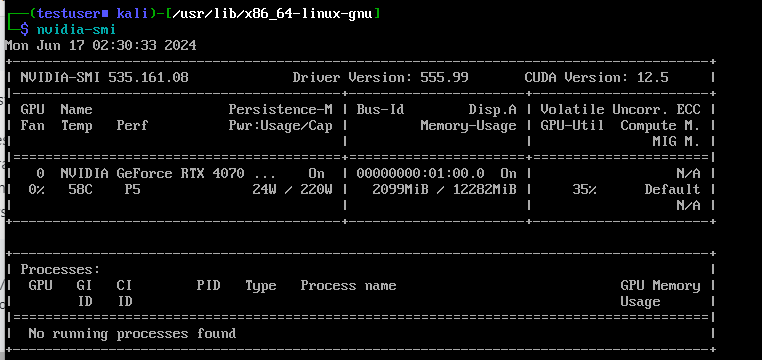
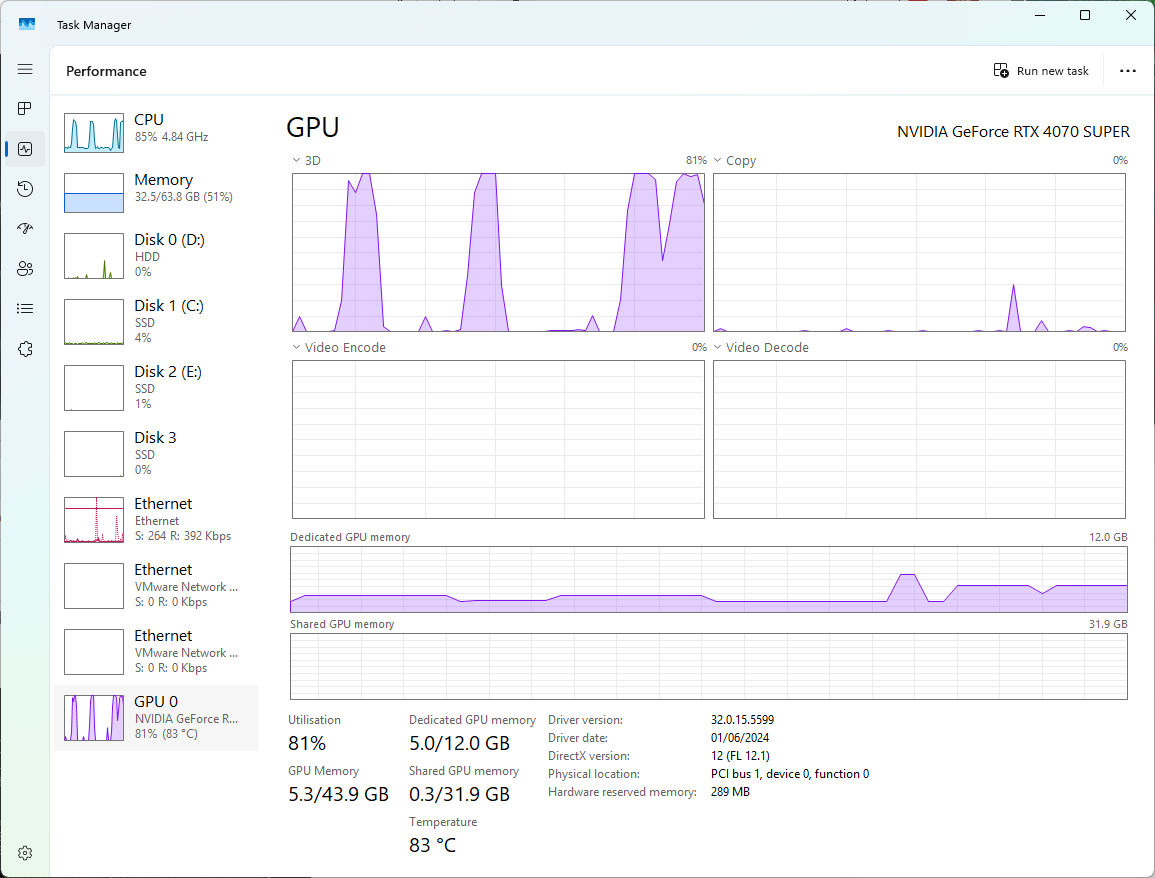
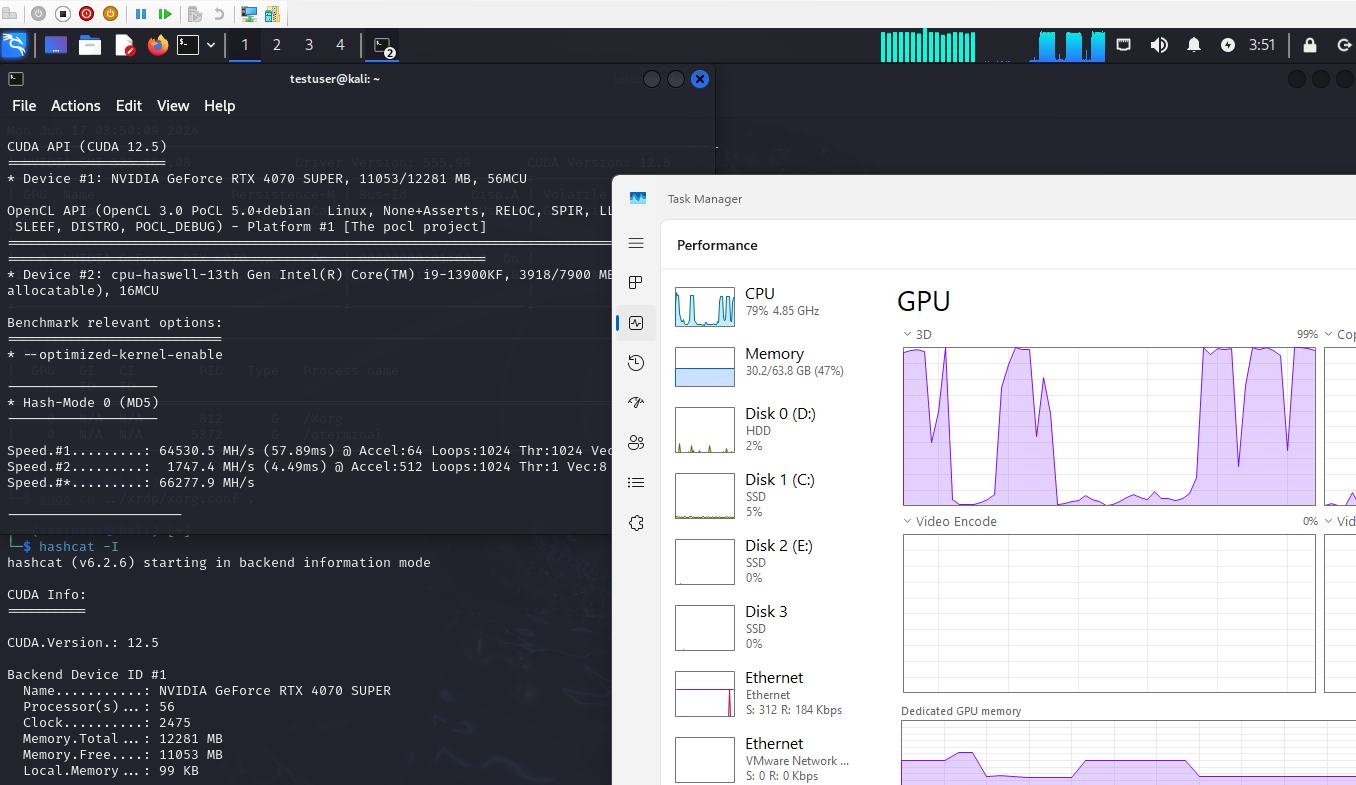
再起動完了後、nvidia-smi を実行すると下記のような表示となり、
また CUDA を用いるアプリケーションにおいても正常に認識され、 Windows 側のタスクマネージャからも GPU が動作していることが分かります。
CUI で計算を行う範囲で十分であれば、ここで設定は完了となります。
(追加) 9. GUI を有効にする
GUI が立ち上がるように設定を入れ込みます。
modesetting ドライバで上手く処理が出来なくなっているのが原因であるため、
・内部に露出している PCI の BusID を調べる
一度 xorg を起動して失敗させ、その中のログから調べるのが手っ取り早いです。
# Xorg の起動を試みる。(失敗してエラーが表示されます)
sudo startx
# ログの中から PCI Bus の ID を見つける
grep "PCI" /var/log/Xorg.0.log
# --
# 実行例
# --
grep "PCI" /var/log/Xorg.0.log
[ 3.668] (--) PCI:*(0@41715:0:0) 1414:008e:0000:0000 rev 0上記の実行例の場合、必要になるのはアットマーク以降の “41715:0:0” になります。
・調べた BusID を設定に入れる
下記の内容を /etc/X11/xorg.conf.d/hv-fbdev.conf として保存 します。
Section "Device"
Identifier "Card0"
Driver "fbdev"
BusID "PCI:(上記で見つけた ID)"
EndSection記入例としては下記のような形になります:
#
# 設定・記入例
#
# sudo vim /etc/X11/xorg.conf.d/hv-fbdev.conf
Section "Device"
Identifier "Card0"
Driver "fbdev"
BusID "PCI:41715:0:0"
EndSectionその後、再起動すると GUI が立ち上がってきます。
(追加)10. Kali Linux の Enhanced Mode を有効にする
Enhanced Mode を有効にすることで、クリップボードの共有やスムーズな描画を使えるようにします。
下記ページに従って設定を行った後、追加の設定を行います。https://www.kali.org/docs/virtualization/install-hyper-v-guest-enhanced-session-mode
・kali-tweaks を実行して、初期設定を行う
下記の順番で遷移して設定を行います。
設定後下記コマンドを入力し、xorg を xrdp を出力先として起動するように設定します。
# Step 9 を実行している場合は、その設定を消去する
sudo rm /etc/X11/xorg.conf.d/hv-fbdev.conf
# xrdp を出力先として起動するように設定する
sudo cp /etc/X11/xrdp/xorg.conf /etc/X11/xorg.conf.d/設定後 VM をシャットダウンします。
・Enhanced Session の接続方式を HVSocket に切替える
管理者権限で起動した PowerShell
# VM の情報を取得。
# (Step 3 や 4 で既に実行済みであれば実行不要)
$vm = Get-VM -Name "<VM名, ワイルドカードも使えます>"
$vm | Set-VM -EnhancedSessionTransportType HVSocket上記が完了したら VM の電源を投入します。
上手く行けば、起動時に下記のようなダイアログが表示されます。
接続を行い、IDとパスワードを入力後、デスクトップが出てくれば完成です。
注意・留意事項等
・マイクロソフト社やその他関連する会社様などから記事の削除・非表示化の指示を受けた場合は予告なく記事を非表示にすることがあります。
・本手法については公式のものではありません。内容に関する質問についてマイクロソフト社やその他の窓口に問い合わせすることはおやめください。また予告なく動作しなくなる場合も考えられます。
・ホスト側のグラフィックドライバの更新などのVM 内のドライバも入れ替える必要がある可能性がある、とのことです(当方環境ではまだ未確認)
執筆に際して参考にした記事など
Hyper-VでGPU(GPU-PV)を利用する方法 (Ubuntu編)https://qiita.com/Hyper-W/items/5ddfc93891f7b620da8a https://gist.github.com/krzys-h/e2def49966aa42bbd3316dfb794f4d6a https://github.com/Nevuly/WSL2-Linux-Kernel-Rolling
検証しながら書いていたら、日が沈んで夜になり、また新たな朝日が昇ってきてしまいました。でもとっても楽しかったのでヨシとします・・!
それではよき GPGPU ライフを VM 内でもお過ごしください!